Data
Data can assume a wide range of types, including numerical data, text, audio and images, and form a fundamental resource for many research projects. Data are also a valuable research output in their own right, given the time taken in many research projects to find, collate and curate data.
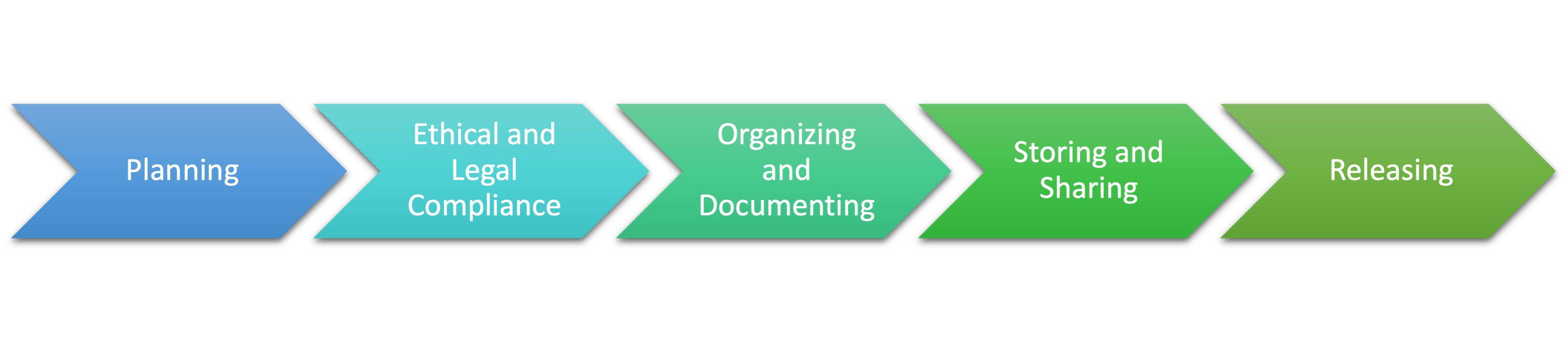
The process cycle describes the use and management of data in a research project.
Each of these steps are described briefly below.
Planning
A data management plan (DMP) should be established in the form of a live document, to identify types of data and related formats that are expected to be used in the project. Data Management Plan templating tools can be used to structure the plan. Research funders often require that a DMP is established during the proposal or project kick-off phases.
Ethical and Legal Compliance
If either personal, sensitive data or confidential data are to be collected during the project, special attention should be given to ensure that legal and ethical issues are addressed in accordance with relevant regulations. This might include storing data on a secure platform, and that data are released (if at all) in an anonymous and secure way. More information available under Licensing.
Organizing and Documenting
Documents and data need to be organized in a way that can be understood and used by future colleagues or researchers. Several steps can be followed to better organize and document the data. These are listed in increasing difficulty, starting with the most straightforward:
- Define a clear folder structure for your data
- If using tabular data, try to reorganise data into “long format”
- Add a license and a readme file to the folder
- Organise the data file(s) into Frictionless Data datapackage by following their data standards and adding a detailed metadata file. The Data Package Creator provides easy-to-use templates to be filled in with information to manually generate a data package and related [metadata][#metadata]
- Create a workflow to document the steps and commands to reproduce the dataset from the raw data
- Incorporate a version control system such as Git
Storing and Sharing
Data need to be stored on a safe platform, and possibly in a way that can be shared across collaborators and retrieved by the interested audiences. There exist several options to publish data online, either on online open data repositories, which provide open access and the possibility to retrieve the data easily, or on private cloud services (e.g. Microsoft Teams, Google Drive, Dropbox), which provide selected access to the files. In the case of personal or confidential data, dedicated private network drives might be recommended instead, as the provide limited access to the data and are not retrievable online. Your institution may be able to support the storage of sensitive data.
Data files can consist of a wide range of file formats:
- comma-separated values (
.csv) files - text (
.txt) files - image (
.jpeg,.png,.bmp,.tiffetc.) files.
To support the reusability of data across research projects, contexts, and applications, it is important that data file formats are not software specific. Where possible, adopt open formats to avoid the need for proprietary software to open the data file in the future.
Releasing
Once a new dataset or data package has been developed, it can be released and published online, and a related Digital Object Identifier (DOI) can be generated. This facilitates other people in citing and making use of it as a new resource or to verify and reproduce existing research that already made use of the dataset. In summary, releasing data, makes the data findable and accessible so that research can be reproduced.
For more information, see release
Related Practices
You may be interested in the following good practices linked to management of data research outputs.
Metadata
Metadata describe a dataset and provide a basic set of information to support the retrievability of data and ensure their correct citation.
Metadata for data packages or datasets must include information about the following:
- Attributions describes who are the contributors to the dataset and their roles
- Licensing clarifying under what conditions the data can be used, modified or shared
In addition, metadata should also include the following:
- Referencing to source material, to provide information regarding where the data come from.
- Other relevant information, which might describe the methodology used for collecting the data, or the data format provided, or additional documentation that might be considered relevant to understand the data and their potential use.
For more information, see the Metadata practice
Referencing
Original data sources must be properly documented and cited.
For more information, see the Referencing practice
Attribution
All contributors i.e. people involved in collecting, processing, structuring and releasing the data - must be acknowledged.
For more information, see the Attribution practice
Release
Releases can be created as soon a version of the data is intended for use for a specific application or as project output. Releases of data should be provided with a Digital Object Identifier (DOI) and a complete metadata file.
For more information, see the Release practice
Licensing
Data must always be associated with a license to clarify what are the legal restrictions (if any) in using, sharing and/or modifying the data. All licenses that apply to the original data sources should also be considered when selecting the license for the derived dataset released or shared as research output. This is to make sure the derived work complies with any potential legal restriction imposed on the original data sources.
For more information, see the Licensing practice
Version control
Version control systems keep track of changes and modifications to data, data formats, data structure and any code used in processing the data.
For more information, see the Version Control practice
Workflow
Workflows help with executing, reusing and reproducing, as well as reporting all steps needed to characterise the processing of data, thus supporting the use of data in the research context.
For more information, see the Workflow practice
Useful resources
- Research Data Management section, from The Turing Way handbook to reproducible, ethical and collaborative data science.
- Data standards for energy modelling for policy support entry, from the u4RIA Modelling for Policy Support forum.